Things Caches Do
There are different kinds of HTTP caches that are useful for different kinds of things. I want to talk about gateway caches – or, “reverse proxy caches” – and consider their effects on modern, dynamic web application design.
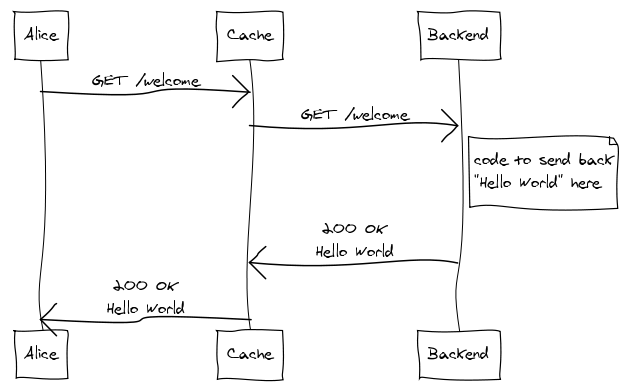
Draw an imaginary vertical line, situated between Alice and Cache, from the very top of the diagram to the very bottom. That line is your public, internet facing interface. In other words, everything from Cache back is “your site” as far as Alice is concerned.
Alice is actually Alice’s web browser, or perhaps some other kind of HTTP user-agent. There’s also Bob and Carol. Gateway caches are primarily interesting when you consider their effects across multiple clients.
Cache is an HTTP gateway cache, like Varnish, Squid in reverse proxy mode, Django’s cache framework, or my personal favorite: rack-cache. In theory, this could also be a CDN, like Akamai.
And that brings us to Backend, a dynamic web application built with only the most modern and sophisticated web framework. Interpreted language, convenient routing, an ORM, slick template language, and various other crap – all adding up to amazing developer productivity. In other words, it’s horribly slow and bloated… and awesome! There’s probably many of these processes, possibly running on multiple machines.
(One would typically have a separate web server -- like Nginx, Apache or lighttpd -- and maybe a load balancer sitting in here as well but that's largely irrelevant to this discussion and has been omitted from the diagrams.)
Expiration
Most people understand the expiration model well enough. You
specify how long a response should be considered “fresh” by including
either or both of the Cache-Control: max-age=N or Expires headers. Caches that understand expiration will not make the same request until the cached version reaches its expiration time and becomes “stale”.
A gateway cache dramatically increases the benefits of providing expiration information in dynamically generated responses. To illustrate, let’s suppose Alice requests a welcome page:
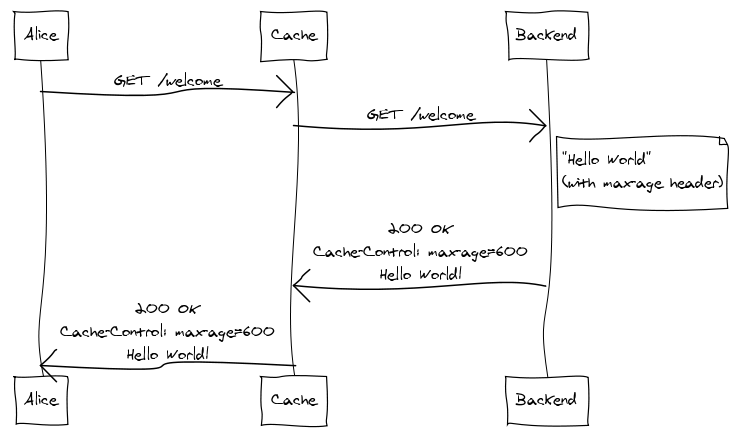
Since the cache has no previous knowledge of the welcome page, it
forwards the request to the backend. The backend generates the
response, including a Cache-Control header that indicates the
response should be considered fresh for ten minutes. The cache then
shoots the response back to Alice while storing a copy for itself.
Thirty seconds later, Bob comes along and requests the same welcome page:
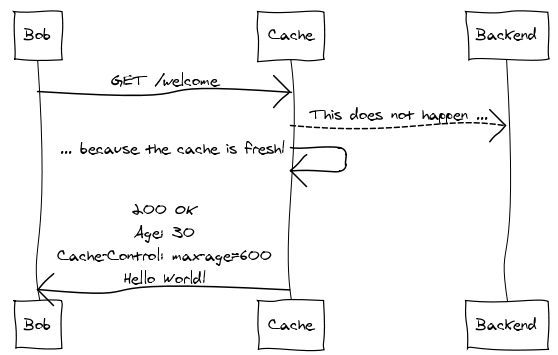
The cache recognizes the request, pulls up the stored response, sees that it’s still fresh, and sends the cached response back to Bob, ignoring the backend entirely.
Note that we’ve experienced no significant bandwidth savings here – the entire response was delivered to both Alice and Bob. We see savings in CPU usage, database round trips, and the various other resources required to generate the response at the backend.
Validation
Expiration is ideal when you can get away with it. Unfortunately, there are many situations where it doesn’t make sense, and this is especially true for heavily dynamic web apps where changes in resource state can occur frequently and unpredictably. The validation model is designed to support these cases.
Again, we’ll suppose Alice makes the initial request for the welcome page:
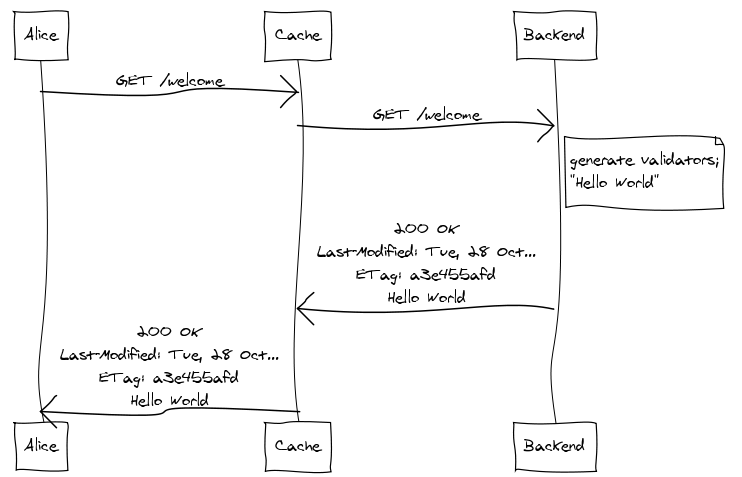
The Last-Modified and ETag header values are called “cache validators” because they can be used by the cache on subsequent
requests to validate the freshness of the stored response without
requiring the backend to generate or transmit the response body. You
don’t need both validators – either one will do, though both have pros
and cons, the details of which are outside the scope of this document.
So Bob comes along at some point after Alice and requests the welcome page:
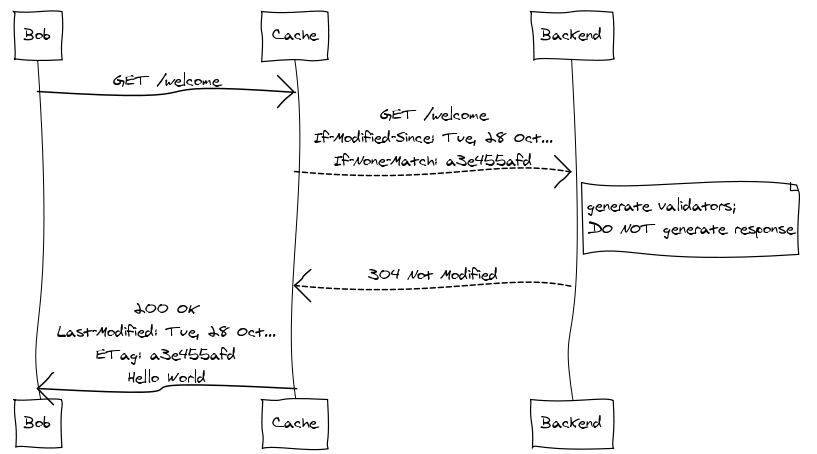
The cache sees that it has a copy of the welcome page but can’t be sure
of its freshness so it needs to pass the request to the backend. But,
before doing so, the cache adds the If-Modified-Since and
If-None-Match headers to the request, setting them to the original response’s Last-Modified and ETag values, respectively. These headers make the request conditional. Once the backend receives the request, it generates the current cache validators, checks them against the values provided in the request, and immediately shoots back a 304 Not Modified response without generating the response body. The cache, having validated the freshness of its copy, is now free to respond to Bob.
This requires a round-trip with the backend, but if the backend generates cache validators up front and in an efficient manner, it can avoid generating the response body. This can be extremely significant. A backend that takes advantage of validation need not generate the same response twice.
Combining Expiration and Validation
The expiration and validation models form the basic foundation of HTTP caching. A response may include expiration information, validation information, both, or neither. So far we’ve seen what each looks like independently. It’s also worth looking at how things work when they’re combined.
Suppose, again, that Alice makes the initial request:
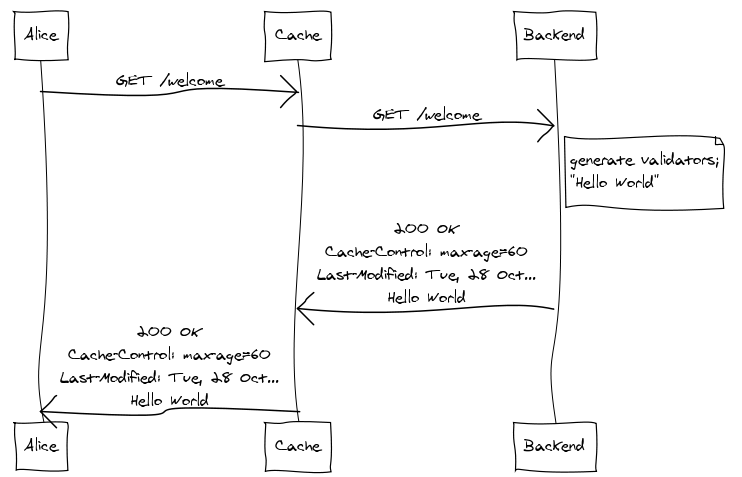
The backend specifies that the response should be considered fresh
for sixty seconds and also includes the Last-Modified cache
validator.
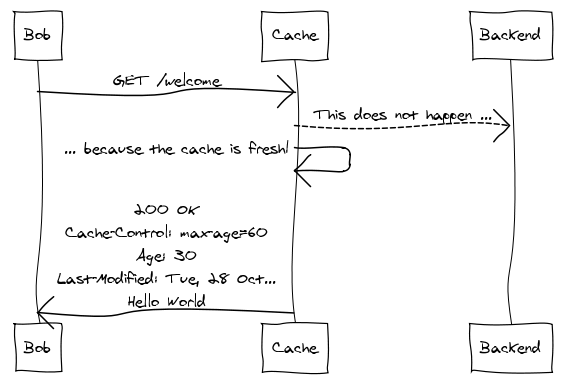
Bob comes along thirty seconds later. Since the response is still fresh, validation is not required; he’s served directly from cache:
But then Carol makes the same request, thirty seconds after Bob:
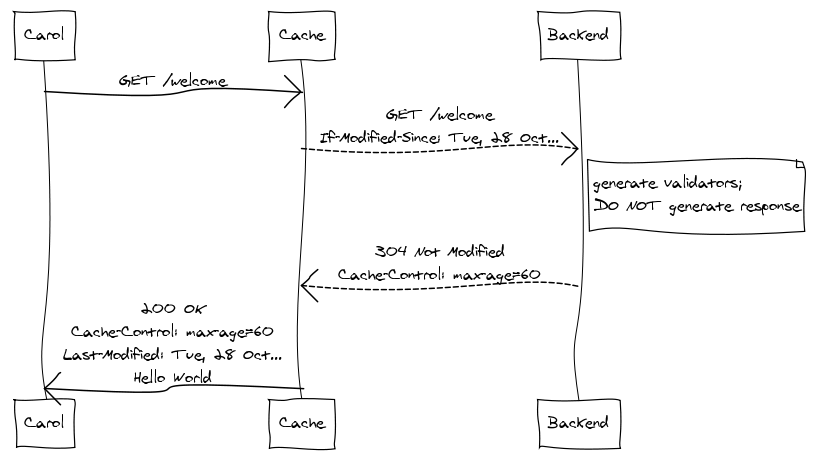
The cache relies on expiration if at all possible before falling back
on validation. Note also that the 304 Not Modified response includes
updated expiration information, so the cache knows that it has another
sixty seconds before it needs to perform another validation request.
More
The basic mechanisms shown here form the conceptual foundation of caching in HTTP – not to mention the Cache architectural constraint as defined by REST. There’s more to it, of course: a cache’s behavior can be further constrained with additional Cache-Control directives, and the Vary header narrows a response’s cache suitability based on headers of subsequent requests.
For a more thorough look at HTTP caching, I suggest Mark Nottingham’s excellent Caching Tutorial for Web Authors and Webmasters. Paul James’s HTTP Caching is also quite good and bit shorter. And, of course, the relevant sections of RFC 2616 are highly recommended.
(Oh, and the diagrams were made using websequencediagrams.com, a very simple, text-based sequence diagram generating web service thingy.)